
Did you know why a lack of data scientists could save AI? The rising applications of artificial intelligence across industries from banking and insurance to manufacturing and even art has boosted demand for data scientists, specifically AI researchers. The relatively new role was even described as “the sexiest job in the 21st century” by the prolific technologist and mathematician, DJ Patil, the former Chief Data Scientist for the United States Office of Science and Technology Policy.
While DJ Patil may understandably be a bit biased, other job ranking platforms give data scientist positions a high grade. Glassdoor ranked data scientists as #3 on its “Best Jobs in America” list for 2020, boasting year-over-year growth in job postings and salary. Data Science also ranked #3 on LinkedIn’s “Emerging Job Report for 2020” — marking the third year in a row the role made the list, showing 37% in annual growth.
The furious demand, driven by the likes of Amazon and Google — and nearly everyone else — has created a shortage of qualified professionals, raising the price of the “product.” Data scientists have reaped the benefits with high and consistently growing salaries.
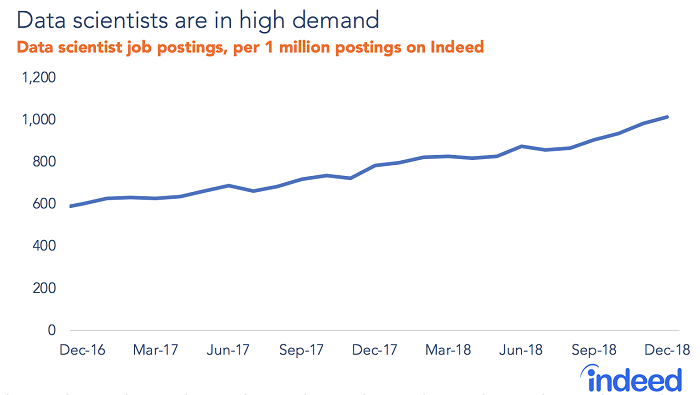
Changes in demand for data scientists
Source: https://images.app.goo.gl/wjuLxnCnbSVTzHkU9
But the market, as markets do, has reacted. The main result has been a “commoditization” of training. Faster, cheaper, more superficial programs are churning out data scientists in several months rather than requiring a master’s degree, which served as the previous industry standard. So we can start to see why a lack of data scientists could save AI.
Taking this all a step in the wrong direction, new, automated machine learning tools (AutoML) make it possible to generate research questions about data without much understanding of data science and research. With a few clicks, data problems are “solved” in ways that can mislead the AI using the algorithms published as open source on the internet. According to a study published in Gartner, by 2020 automation is expected to power about 40% of data research tasks.
The combination of inexperienced data scientists and automation tools can lead to solutions with reduced, misguided, and biased performance. This is a possible dangerous outcome of the trend that could undermine the trust of AI end consumers.
Supply and Demand
Will the new supply actually satisfy the demand? The answer depends on whether the industry ultimately decides to accept these shortcuts as good enough for the tasks at hand. What’s clear is that the field will be flooded with more people conducting data research without the theoretical depth that has characterized this community so far.
In 2018, Gartner defined this new hybrid job as “citizen data scientists.” Does it sound less sexy? Definitely. Does that make the in-between function unnecessary? Not necessarily.
Just as the field of data science grows into its awkward teenage years, AI in the wider sense is feeling similar growing pains. Though the technology continues to disrupt industries, it’s also difficult to implement. According to VentureBeat, 87% of AI projects in the US fail to reach production. Many companies don’t have the internal capabilities or AI centers of excellence, to take a solution from the theoretical proof point to a part of their operations.
This wide-spread implementation failure cannot be reversed by education and staffing alone — but education and staffing can help.
Much ink has been spilled on the question of whether true data scientists are “unicorns”: a superman/superwoman combination, part gifted researcher, skilled software developer, and savant of the business world — and as such, difficult to find and invaluable.
That type of role feels unrealistic in today’s increasingly automated landscape; and searching for superhero-type candidates is certainly not a scalable strategy for success.
I believe that citizen data scientists could significantly increase the chances of AI success by resolving the supply gap – but only if they are used as a compliment to data scientists, rather than substitutes. Companies need to build teams with complementary skills: the researcher who knows the facets of algorithms, the data product manager who knows the needs of the customer, and the machine learning engineer who knows how to implement algorithms from design to deployment in the production environment.
Such a model is also more likely to produce product managers specialized with AI, who can come down several floors from the ivory tower of models and algorithms and help customers understand in concrete, client-focused, and business-oriented terms what this type of technology can do for them. It is a function that has been predictably lacking until now.
Data Scientists
Citizen data scientists, meanwhile, can ease the more pedestrian burdens often left for data scientists to handle, giving them capacity to aim higher. This complementary function could build new internal capacity that helps companies achieve more and potentially democratize the field of AI.
Another unintended benefit of a hybrid approach is diversity. Due to the differences in education and experience required, a multi-level team of complementary data scientists will bring different experiences and perspectives to the solutions they are building; it is something that has been lacking somewhat in the field of AI.
As with most things, we must practice moderation as we address the growing demand for data science. The search for the data science unicorns could bankrupt a company, while overstaffing with lesser-trained substitutes could sink a product. Let’s make employing both the data scientists, to make AI more widely accessible.







{kind=link}