
The debate about whether open source LLMs are good enough for production is over.
DeepSeek V4, Llama 4, Qwen 3.5, Mistral Large 3, these models now rival or match closed models on most practical benchmarks. The licensing is permissive. The pricing for self-hosted inference is a fraction of API costs at scale. The community support has matured enough that deployment is no longer an exotic engineering exercise.
The question has shifted. It’s no longer “can we use open source models in production?” It’s “do we have the infrastructure to use them well?” For most teams, the answer to the second question is no, and that gap is costing them more than they realize.
Table of contents
What “Production-Ready” Actually Means Now
Open source models in 2026 are production-ready in the sense that the model quality is there. What that doesn’t mean is that the operational infrastructure around them is automatically in place.
A closed model API gives you reliability, uptime guarantees, managed scaling, and a single billing relationship. You call the endpoint, you get a response, you pay the invoice. The infrastructure complexity is hidden.
Open source models accessed via hosted inference providers give you more flexibility, model choice, cost optimization, and no vendor dependency, but they come with an operational surface area you have to manage: multiple provider relationships, different API formats per provider, no built-in fallback if a provider goes down, and fragmented cost tracking across invoices.
The model being good is necessary but not sufficient. The question is whether your stack handles what happens when things go wrong, and things always go wrong.
The Three Infrastructure Gaps That Matter
1. API format fragmentation
Llama hosted on Together AI returns responses in a different format than Llama hosted on Fireworks, which differs again from a self-hosted vLLM deployment. Qwen’s tool call schema differs from OpenAI’s. Switching between providers, or between open and closed models, requires normalization logic, either in your application code or in a gateway layer.
Teams that build this normalization directly into application code pay a recurring tax every time they add a model or switch a provider. It’s not hard work, but it adds up: a few days per model, a few more to test, a few more when a provider updates their schema.
2. Fallback and reliability across providers
Hosted open source inference providers have varying reliability profiles. A provider optimized for cost may have higher latency spikes. A provider optimized for speed may have lower availability during peak demand. Without fallback logic, a provider hiccup becomes a user-facing error.
The practical solution is multi-provider routing: run your open source model traffic across two or more providers, and fail over automatically when one underperforms. Most teams don’t have this in place because it requires infrastructure investment upfront. The first incident that would have been caught by fallback tends to accelerate the timeline.
3. Cost visibility across a mixed model fleet
Teams running a mix of open source and closed models, which is most teams in 2026, face a fragmented billing picture. Closed model costs come from provider APIs. Open source costs come from hosted inference providers or self-hosted compute. Without a central layer aggregating spend, understanding your actual AI cost requires reconciling multiple sources.
This matters most when you’re trying to answer the question every engineering leader eventually asks: “Which model is driving the most cost, and is it worth it?” Without per-request attribution across your whole fleet, the answer requires manual work every time.
The Opportunity in the Gap
The teams that close this infrastructure gap gain a structural advantage: they can use the best model for each task across the full spectrum of open and closed options, without the operational overhead growing proportionally.
In practice, this means:
Routing cost-sensitive tasks to open source models where quality is equivalent. Running closed models for tasks where the quality differential justifies the cost, switching providers or models without application code changes, and seeing the full cost picture in one place
The open source model landscape is moving fast enough that the best option today may not be the best option in three months. Infrastructure that lets you switch quickly is worth more than any single model choice.
What Good Infrastructure Looks Like
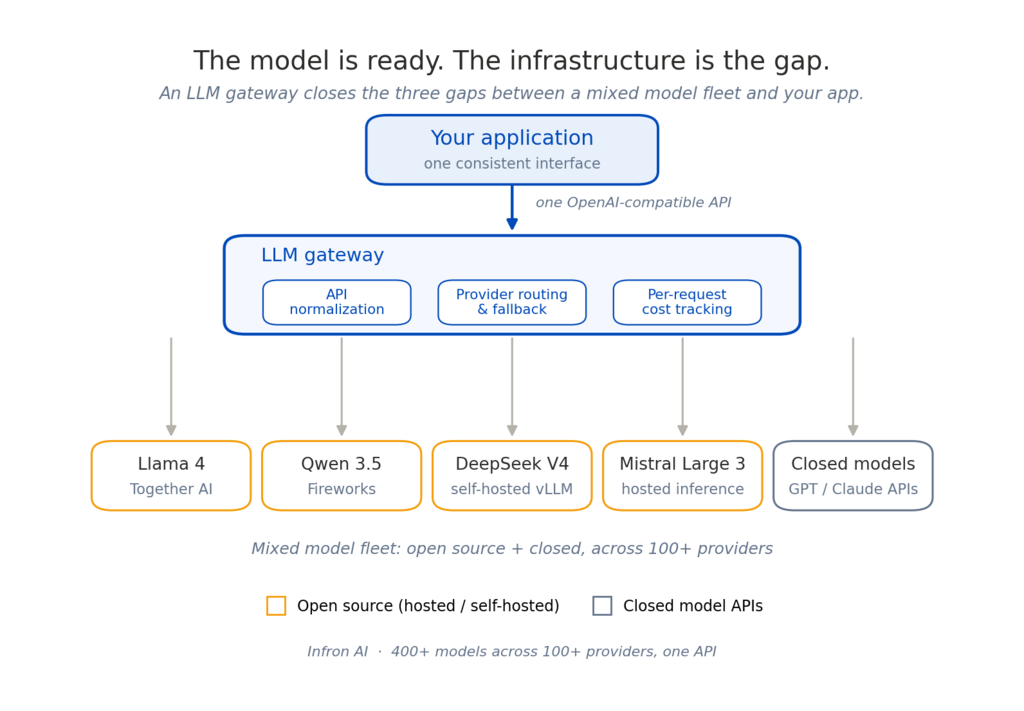
The teams getting this right aren’t building custom routing layers from scratch. They’re using an LLM gateway as the abstraction layer that handles API normalization, provider routing, fallback, and cost tracking, and then making model decisions on top of that foundation.
The gateway doesn’t care whether the model underneath is open source or closed. It exposes a consistent interface, routes to wherever the model lives, tracks what it costs, and fails over when something goes wrong. The model portfolio becomes a configuration decision rather than an infrastructure project.
Open source models are ready. The infrastructure to use them at their full potential is the remaining gap, and it’s a solvable one.
Infron gives you access to 400+ models including leading open source options across 100+ providers, through a single OpenAI-compatible API with automatic fallback and per-request cost tracking. The infrastructure layer that makes your open source model strategy actually work.







{kind=link}