
Change Data Capture in the real-time streaming environment can be stitched together through a data pipeline-based solution leveraging CDC architecture and different tools that exist today
Understanding Real-time Data Capture
Most transactions (operations) in the current world are real-time, resulting in constant CRUD operations (Create, Read, Update, and Delete) on transactional systems. However, typical data warehouse implementations have been D-1, where reports and dashboards always reflect KPIs as of yesterday. This was mainly due to:
- The defined ETL processes, and
- The pipelines were created to work in batch mode.
Today in current environments, reports and dashboards should be as real-time as possible. While ‘Change Data Capture‘ as a framework is fairly standardized and is enabled through different tools, the focus was not really on real-time data capture. CDC, as a design pattern, allows the process to capture these types of changes and provides efficient integration with the rest of the enterprise systems. The approach of capturing and processing only the changed data leads to all-round efficiency improvement, in terms of computing, performance, storage, and costs of ownership.
Flexibility with Options
We can achieve the CDC approach in multiple ways:
- By developing ‘Database Triggers’ at the source application database to extract, based on the change that happened.
- By implementing a comparison logic in the application layer to identify the changed
data and create an alternate, yet continuous, pipeline to capture changed data. - By implementing a dedicated CDC tool such as GoldenGate, Syncsort, etc.
- By implementing CDC platforms such as Confluent, Striim, Attunity, etc.
- Leveraging the CDC capture mechanism provided by the databases, such as
SQLServer. - Extracting changed data from the database transaction log files.
There are both advantages and disadvantages to each of these approaches. A few of them are listed below:
- The Database Triggers Approach is a time-tested traditional approach, however with the caveat that it impacts the operating system performance.
- Application Logic/Triggers is an approach that can only work if the record passes through the application layer. For example, a deleted record may not pass
through the application layer and hence, gets missed in this approach. - CDC tools are typically expensive and may not be in the affordability range for all projects.
- The CDC tables feature is provided by only a few database vendors.
- The Database Log Files-based Approach is technically ideal, as it does not affect the OLTP system and can access all types of database changes. However, log-based CDC drivers for all database systems are not available.
It’s Best Presented This Way
Our analysis and findings regarding implementing CDC-based real-time data integration using Kafka as the messaging engine are presented below.
1. Context:
Extract the changed data from the source system (Azure SQL) in real-time and process / transform it as a stream, using spark streaming, and store it in a star
schema-modelled RedShift database.
The target state architecture for CDC integration is as follows:
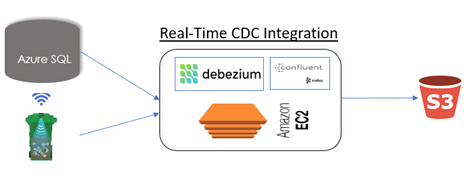
2. Key Concepts and Technologies:
- Live Data Extraction and CDC using Confluent Kafka
- Data Transformation and Processing using PySpark Structured Streaming
- Amazon Redshift Data warehouse design, setup and loading
- Big Data Analytics on Amazon RedShift using Power BI
Debezium Drivers:
JDBC drivers are used for source connection, and Debezium CDC drivers are used in our implementation. Separate configuration files have been created to cater to inserts and updates at the source system
Confluent Kafka:
Confluent is a fully managed Apache Kafka service that provides a Real-Time Stream Processing Platform for enterprises. Kafka is a highly scalable, fault-tolerant distributed system that provides a powerful event streaming platform through a publish/subscribe messaging service. Data producers publish messages in the form of Kafka topics, and data consumers subscribe to these topics to receive data.
Property Files:
Two property files are created: one for the source property file (for the Azure SQL database) and the second for the sink property file (for the S3 bucket).
Properties Files
The source property file contains credentials information for source name, password, database name, username and topic names, and JDBC Source connectors class information.
The sink properties file contains details of S3 as below:
- S3 bucket name
- S3 location
- Default flush size as 3 records
Kafka Modes:
Kafka can be implemented in the following modes:
Incrementing: Uses a strictly incrementing column on each table to detect only new rows. Note that this will not detect modifications or
deletions of existing rows.
Bulk: Performs a bulk load of the entire table each time it is polled.
Timestamp: This method uses a timestamp (or timestamp-like) column to detect new and modified rows. It assumes the column is updated with each write and that values are monotonically incrementing but not necessarily unique.
Timestamp + Incrementing: This method uses two columns: a timestamp column that detects new and modified rows and a strictly incrementing column that provides a globally unique ID for updates so that each row can be assigned a unique stream offset.
Query: Uses a custom query for polling the data from the source system
Timestamp + Incrementing mode of Kafka
We implemented the Timestamp + Incrementing mode of Kafka as our system requires capturing both incremental (new records) and updated records.
a. Data Pipeline:
Kafka reads data from the Azure SQL database and writes in Kafka’s topic. The data pipeline consists of reading data from the Kafka topic and writing the raw data in the S3 bucket. Significant transformations, integrations, and aggregations are implemented in Spark streaming jobs and are written in S3, and then subsequently into the RedShift database.
b. PySpark:
Spark is a distributed processing framework for handling big data applications. It uses In-memory Caching and Optimized Query Execution for querying against large-scale data in a fast and efficient manner. PySpark is the Python API for Spark. While CDC is captured by Kafka, Spark implements transformations and loads them into RedShift. A custom module is developed in Spark to handle the varying data types and column names between source systems and RedShift.
The following configurations are done in the custom module:
| Kafka | S3 | RedShift |
| HostName | S3 Path | Database Name |
| MultipleTopicPrefix | AccessKeys | Master User |
| Password | ||
| JDBC URL |
- Read stream: To read the data continuously from the Kafka topic.
- Starting Offset: The “Earliest” offset is set to prevent data loss in case of failures.
- Write Stream: To write data continuously to RedShift.
- Temp Directory: Path to S3 data storage is given for continuous writing to RedShift.
- Checkpoint Location: An HDFS path is given where the data offset is stored so that duplication does not happen.
c. Redshift Data Modelling:
Amazon Redshift is the fastest cloud-based data warehouse service for running high-performance queries on petabytes of data. The Redshift database is modelled using the star schema approach.
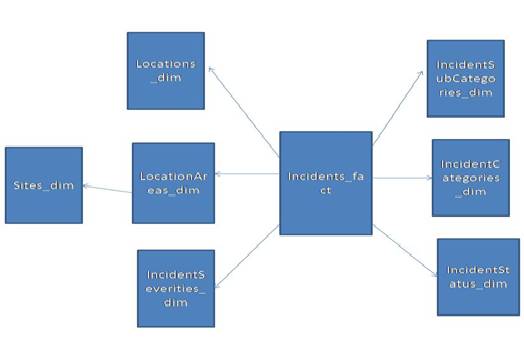
Final Thoughts
Change Data Capture, in the real-time streaming environment, can be stitched together through a data pipeline-based solution leveraging different tools that exist
today. The implementation, shown here, powers the dashboards for a Risk Management Platform that is used by leading malls and airports across Australia
and New Zealand. This is a low-cost and robust implementation that was executed by RoundSqr.







{kind=link}
Comments are closed.