")
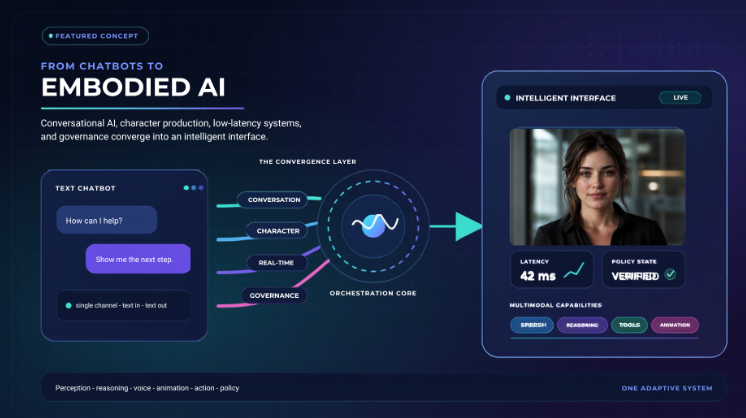
How conversational AI, character production, low-latency systems, and governance are converging into a new class of intelligent interface in embodied AI.
Most AI interfaces still look the same: a text box, a blinking cursor, and a reply. That format works for simple queries. It begins to break down when a user needs guidance, demonstration, or anything that depends on knowing where to look or what to do next.
Real-time digital humans change that equation. Instead of hiding intelligence behind a chat window, embodied AI gives it a visible and responsive form that can speak, gesture, direct attention, and complete workflow steps alongside the user.
The shift is not cosmetic. It represents a fundamental change in how AI communicates and acts.
Key Takeaways
- Embodied AI transforms traditional AI interfaces by integrating human-like responses and visible behaviors into digital interactions.
- It leverages real-time digital humans to improve user guidance through speech, gestures, and gaze, enhancing task execution.
- Producing convincing digital humans requires character production and agent engineering to work in tandem.
- Embodied AI suits complex tasks where visual presence resolves ambiguity and supports comprehension, such as training and onboarding.
- Designing embodied AI should prioritize workflow tasks first, ensuring effective interaction before scaling applications.
Table of contents
What Embodied AI Means
Embodied AI refers to artificial intelligence expressed through an observable form that can perceive context, maintain state, reason, and act within a physical or virtual environment.
That form may be a physical robot, a real-time 3D avatar, a game-engine character, or a screen-based digital human. What makes the system embodied is not photorealism alone. It is the feedback loop between perception, reasoning, action, and visible behavior.
For a digital human, embodiment is as much behavioral as visual. Speech, gaze, facial expression, gesture, timing, and the ability to affect an interface or workflow all help make the agent’s internal state understandable to the user. Mimic Minds’ embodied AI overview describes this as an agent perceiving context and expressing actions through a physical or virtual body.
Why Text-Only AI Has Hit a Wall
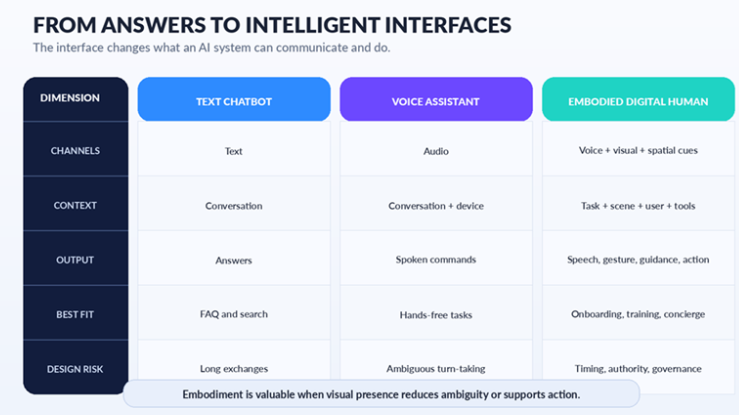
Chatbots are fast to deploy and familiar to users. For FAQ handling, basic triage, or internal search, they remain a reasonable choice. Their limits become more visible when the interaction itself carries meaning.
Text cannot naturally show where to look. It cannot demonstrate a physical procedure, signal turn-taking, or acknowledge an interruption in the way a person would. Voice assistants solve part of the problem because hands-free interaction is useful, but voice without a visual layer can still leave users guessing which control, field, or step the system is referring to.
Embodied AI fills that gap. A digital human can orient its gaze toward a relevant element, gesture toward the next step, pause when interrupted, and signal whether it is listening, processing, or ready to continue.
These cues do not necessarily make the underlying model more intelligent. They make the system’s state more legible, and that distinction matters in complex or high-impact interactions.
What a Production-Ready Digital Human Actually Requires
Building a convincing digital human interface requires two disciplines that are often treated separately. Both must work together.
The first is character production: 3D modeling or scanning, facial and body rigging, motion capture, animation, real-time optimization, and rendering. Mimic Productions works across this pipeline, producing photorealistic digital humans and optimized assets for real-time engines and live character performance.
Mimic Productions’ project credits include motion capture for The Matrix Awakens: An Unreal Engine 5 Experience. The company separately states that its founders’ earlier feature-film credits include Avatar and Rise of the Planet of the Apes. This distinction keeps the studio’s direct project work separate from the founders’ previous film credits.
The second discipline is agent engineering: conversational AI, knowledge grounding, persona design, tool integrations, analytics, and policy controls. Mimic Minds represents this platform layer, combining digital-human design with conversational AI and real-time interaction for enterprise, training, events, and customer-experience deployments.
A common failure mode in avatar pilots is investing heavily in one layer while underdeveloping the other. A strong language model cannot compensate for weak animation or unconvincing rendering. A photorealistic character cannot compensate for poor grounding, inappropriate responses, or unclear escalation paths.
Production-grade embodied AI requires both layers to work in sync.
The Technology Stack for Embodied AI, in Plain Terms
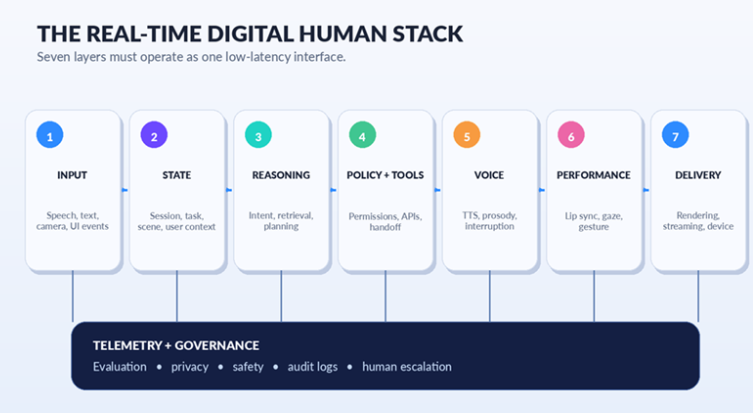
A real-time digital human operates as a connected, low-latency pipeline. Every layer contributes to whether the interaction feels responsive or broken.
Input and Perception
Input and perception come first. The system may receive speech, text, interface events, optional camera input for gaze or gesture detection, and context from the host application.
That context might include:
· The page currently being viewed
· The active step in a process
· The state of a form
· The user’s selected product
· The location of a relevant control
· The current stage of an onboarding flow
State and Grounding
A state layer tracks conversation history, user context, task progress, and relevant information from CRM, knowledge, or workflow systems.
This grounding separates a capable assistant from a character that simply talks. It gives the agent access to the information required for the current task while helping restrict it from answering outside its approved scope.
Reasoning and Tool Use
The reasoning layer determines the next action.
That action may be:
· A spoken response
· A highlighted interface element
· A knowledge-base lookup
· A scheduled appointment
· An updated record
· A support ticket
· A request for confirmation
· An escalation to a human agent
Each tool the agent can call should have a narrow and clearly defined scope. An avatar that can explain a product does not automatically need permission to modify customer records or process payments.
Speech and Character Performance
Above the reasoning layer sits speech generation with natural pacing, facial animation synchronized to the audio output, gaze behavior, expression selection, gesture control, and interruption handling.
The language model should not directly control every expression or movement. A controlled behavior layer can map validated conversational states to approved actions, such as attentive listening, neutral explanation, confirmation, or concern.
This reduces the risk of behavior that conflicts with the meaning of the conversation.
Rendering and Governance
The character may be rendered locally, inside a browser or real-time engine, or delivered through cloud streaming.
The final layer covers telemetry and governance: recording what happened, identifying failures, tracking performance, reviewing escalations, and improving the system over time.
Embodied AI Latency and Interruption Handling
In an embodied interface, waiting is visible.
The latency budget includes audio capture, speech detection, transcription, knowledge retrieval, model generation, policy checks, speech synthesis, facial animation, rendering, and network delivery. A delay at any stage can create an awkward silence or make the character appear disconnected from the conversation.
The system must also support interruption handling, often called barge-in. When a user begins speaking while the avatar is responding, the current voice output, facial animation, gesture, and pending response should stop together. Late audio or animation events must be discarded so that the previous answer does not continue after the conversation has moved on.
Without this synchronization, even an accurate response can feel delayed, unnatural, or unreliable.
A weak link anywhere in the pipeline becomes visible to the user. Slow responses, mismatched lip-sync, frozen expressions, or a smile during a complaint can undermine trust regardless of how accurate the underlying model is.
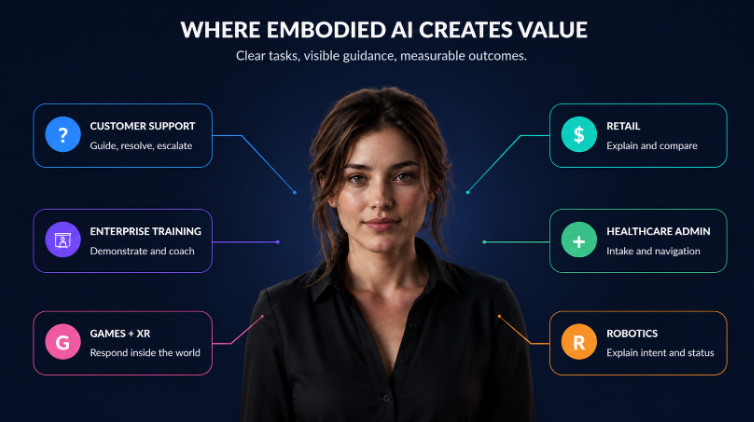
Where Embodied AI Earns Its Place
Not every interaction benefits from a digital human. A password reset or simple FAQ may still be faster in text.
Embodiment earns its place when visual presence reduces ambiguity, supports comprehension, improves the flow of a complex task, or helps users understand what the AI system is doing.
Customer Onboarding
The agent can guide users through account setup, draw attention to relevant fields, explain unfamiliar steps, and hand unresolved issues to a human team.
Enterprise Training and Simulation
A digital human can demonstrate procedures, run role-play scenarios, provide consistent instructions, and respond to trainee questions.
Guided Retail
The avatar can ask clarifying questions, present relevant features, guide product comparison, and connect with inventory, booking, or customer systems.
Healthcare Administration
Potential applications include intake, navigation, appointment preparation, and administrative guidance, provided the system uses strict privacy controls and immediately escalates clinical questions.
Games and XR
Real-time characters connected to natural language, player context, and narrative state can turn dialogue from a fixed menu into a responsive system.
Robotics and Public Environments
A screen-based or projected persona can help a machine explain what it is doing, communicate intent, and receive instructions from people who have never used that system before.
Safety and Trust Are Part of the Embodied AI Design
A confident, human-like interface may lead users to extend more trust than the system deserves. That asymmetry requires deliberate design choices rather than afterthoughts.
Every deployment should clearly disclose that the user is interacting with AI. High-impact actions, such as updating records, processing payments, submitting forms, or making consequential recommendations, should require explicit confirmation and accessible human-review paths.
The NIST AI Risk Management Framework offers a voluntary structure for managing risks to individuals, organizations, and society across AI design, development, deployment, and evaluation. NIST currently notes that AI RMF 1.0 is being revised, so publishers should link to the live framework page rather than present the original version as a fixed final standard.
The OWASP Top 10 for LLM and Generative AI Applications provides additional guidance on risks including sensitive-information disclosure, improper output handling, excessive agency, system-prompt leakage, and misinformation.
Trust also depends on behavioral coherence.
An avatar that smiles during a serious complaint, looks away during a consent request, or continues speaking after an interruption sends the wrong signal even when its words are technically accurate.
Animation and conversational behavior are not decoration. They are part of the trust signal.
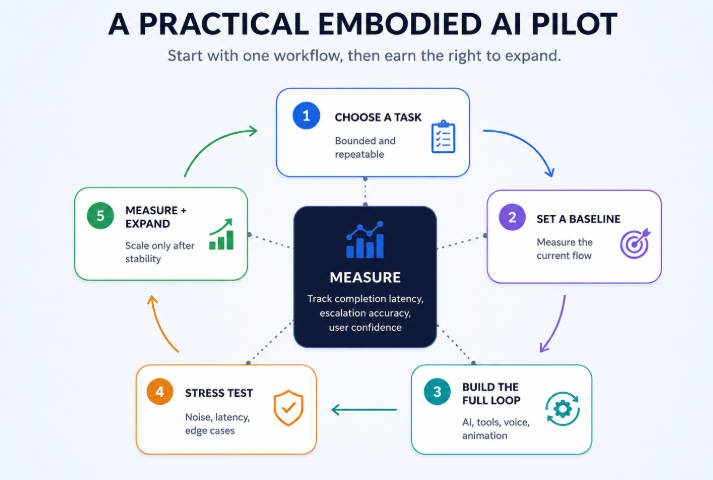
How to Start Embodied AI: One Task, One Workflow
The most common mistake in embodied AI pilots is starting with a character demonstration instead of a workflow.
A digital human that can do everything for everyone is a design problem, not a product.
Start with one bounded and repeatable task, such as:
· Customer onboarding
· A training module
· Lead qualification
· Event navigation
· Product explanation
· Appointment preparation
Measure how the task performs today using metrics such as completion rate, time to resolution, abandonment, error rate, and escalation frequency.
Next, build the full interaction loop covering input, state, reasoning, speech, animation, workflow action, and human handoff. Test it as one complete experience rather than validating every component in isolation.
Testing should reflect realistic conditions:
· Different accents
· Background noise
· User interruptions
· Slow networks
· Unsupported questions
· Incomplete information
· Failed tool calls
· Requests for a human
· Conflicting user instructions
Track task completion, response latency, escalation quality, and user comprehension rather than novelty.
Once the agent handles one role reliably, the organization can expand to new languages, channels, tasks, and knowledge domains. Scaling before the first workflow is stable only creates a larger source of confusion.
The Interface Is Becoming the Agent
Chatbots separated intelligence from presentation. The interface was a neutral container.
Embodied AI collapses that separation. Voice, face, timing, expression, and gesture are no longer decorative outputs. They become the means by which the agent communicates uncertainty, directs attention, requests confirmation, acknowledges interruption, and signals progress.
The organizations that get this right will not begin by asking how human the avatar can look. They will ask what the interface needs to do to make the AI understandable, useful, and safe.
Real-time digital humans are becoming intelligent interfaces because they connect two elements that were previously treated separately: the agent that can reason and act, and the form that makes those actions legible to people.






")
{kind=link}