
For years, analytics teams operated on a simple premise: define a metric once, reuse it everywhere, and trust every dashboard tells the same story. The semantic layer made that possible. It acted as a contract between business logic and data systems, turning messy SQL into something consistent and easier to trust. However, the rise of agent-driven analytics is challenging this traditional model by demanding more flexible, dynamic architectures that can support autonomous data exploration and decision-making.
It worked because the questions were predictable. Analysts moved step by step, and teams had time to extend the model when needed. That alignment no longer holds. You can see it in rising complexity, higher overhead, and even simple questions getting harder to answer.
Agent-driven analytics changes how questions appear. Queries are generated continuously, often in combinations no human planned. Systems built for controlled exploration now face open-ended reasoning at machine speed.
This is not a small scaling issue. It is a mismatch between the architecture and how things actually work today.
Key Takeaways
- Traditional semantic layers helped standardize analytics but now struggle with dynamic queries.
- Agent-driven analytics introduces unpredictability, leading to complex query requirements beyond predefined models.
- A context engine shifts semantic resolution to runtime, allowing definitions to emerge from usage rather than static setups.
- Organizations must ensure governance and visibility as they adapt to more flexible, real-time analytics environments.
- CTOs should recognize when their semantic layers become bottlenecks, marking the transition to agent-driven analytics.
Table of contents
- The Semantic Layer Solved the Right Problem at the Time
- What Breaks When Agents Generate Queries
- From Predefined Models to Context Engines
- Federated Execution and the Rise of the Query Planner
- Why This Represents a Category Shift
- Governance, Auditability, and Operational Reality
- What This Means for CTOs
- The Assumptions Have Changed
The Semantic Layer Solved the Right Problem at the Time
The semantic layer emerged to bring order to analytics chaos. Tools built around a semantic layer defined business logic once and translated it into consistent queries. Platforms later reinforced this idea through centralized metric definitions, ensuring every team spoke the same language.
That design worked because questions were slow and repetitive. BI teams could manage a small set of definitions. Dashboards reused the same queries with minor changes. Dimensional models, such as star schemas, made common joins efficient while discouraging everything else.
The system did not need to anticipate every question, only those that showed up often.
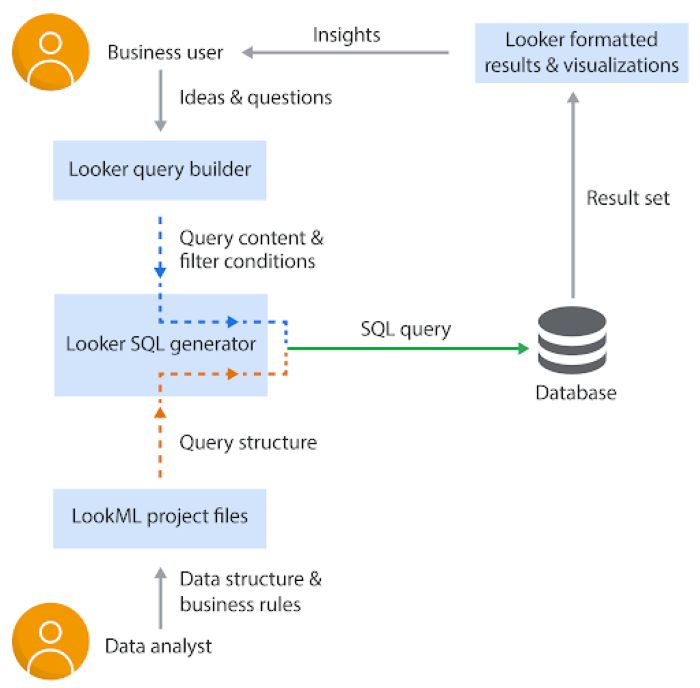
Visual 1: Traditional semantic layer translating predefined models into SQL queries
At this stage, the flow remains controlled. Business users ask questions, the semantic layer translates them, and the database returns consistent results. The structure enforces discipline. It also limits flexibility.
What Breaks When Agents Generate Queries
Agents remove the pacing constraint entirely.
A single interaction can trigger dozens of queries. Many explore relationships that were never modeled. The long tail becomes the default, not the exception.
The issue is not query volume. Maintenance scales with query diversity.
Systems built around predefined models struggle here. Each new question introduces joins, edge cases, and definitions. Dimensional models optimize a curated set of joins, but agent-generated queries cross those boundaries by default. Maintenance grows faster than the team can respond.
The semantic layer starts to act like a forecasting system, assuming a small group can predict what the business will need ahead of time. That assumption breaks when queries emerge dynamically from agent-driven analytics systems operating across distributed data.
The friction shows up quickly. Agents request metrics that do not exist, cross boundaries, hit unindexed schemas, and rely on relationships nobody planned for.
Agents route around gaps in the model, and those gaps widen because unused definitions rarely get fixed.
From Predefined Models to Context Engines

Image: Connected data systems resolving meaning at runtime | Digineer Station – Shutterstock
Extending the semantic layer does not solve the problem. It only delays it. The alternative is to change how meaning is resolved.
A context engine shifts semantic work to runtime, learning from usage instead of relying on upfront definitions. This is the direction we at Wisdom AI are actively exploring in production systems. Definitions emerge through activity rather than prediction:
- Meaning evolves through usage
- Conflicts show up during execution
- Ownership sits with the teams closest to the data
- Definitions improve gradually instead of through large redesigns
Take a common scenario. Marketing defines “qualified lead” one way. Sales defines it differently. In a static model, that conflict sits unresolved until someone updates the schema. In a context-driven system, the conflict appears when the query runs. The system surfaces it immediately and routes it to the right owner.
The model stays active. Semantic work shifts from one-time design to continuous adaptation.
Federated Execution and the Rise of the Query Planner
Once semantics move to runtime, execution must follow.
Modern analytics systems rely on federated query execution across multiple data systems. Instead of forcing all data into a central warehouse, queries reach directly across operational databases, cloud warehouses, SaaS platforms, and file systems.
This shift moves the bottleneck to query planning. The query planner becomes the core of the system. The planner decides which sources to access, how to join them, where to run computation, and how to balance cost, latency, and completeness.
The warehouse no longer owns the logic; the planner does. This removes two persistent costs in the traditional stack. The modeling tax shrinks because definitions evolve from usage. The pipeline tax shrinks because long-tail questions no longer require dedicated pipelines.
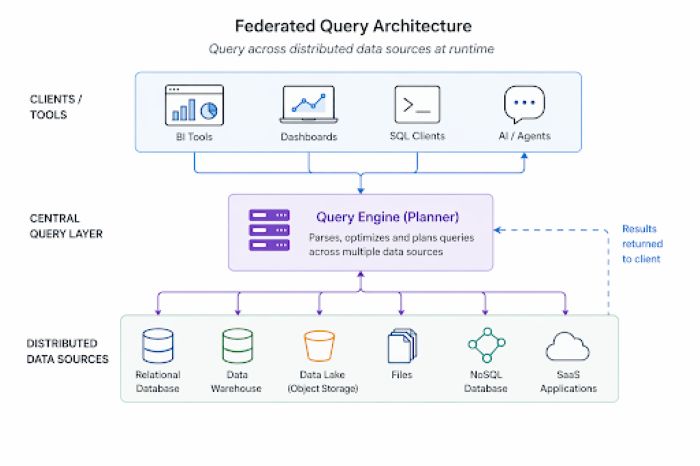
Visual 2: Federated query architecture supporting runtime planning across distributed data sources.
This diagram reflects the inversion. Queries originate from multiple tools and agents. The planner orchestrates execution across systems, then returns results. The architecture adapts to each query instead of forcing it into a predefined model.
Why This Represents a Category Shift
The semantic layer assumes predictability. It locks definitions in advance and optimizes for repeated queries. That model works when the cost of error is high and the pace of change is low.
A context-driven system assumes unpredictability. It resolves meaning during execution and adjusts continuously. The cost of error becomes manageable because the system can correct itself in place.
These assumptions lead to different cost structures. One invests heavily up front, the other spreads the work over time. Trying to combine them leads to friction. One model dominates the other.
This is not an upgrade to the semantic layer. It is a response to a different class of problems.
Governance, Auditability, and Operational Reality

Image: Data governance ensuring control and trust | Koupei Studio – Shutterstock
Shifting to runtime systems introduces new requirements. Flexibility increases, but so does the need for control.
Organizations need visibility into decisions, metric interpretation, and query execution. That requirement grows as systems move into production at scale. Trust comes down to a few things:
- Results must be reproducible
- Query execution must remain deterministic
- Data lineage must stay visible
- Metric interpretation must be transparent
Without these, it becomes hard to use agent-driven analytics in high-stakes environments.
The organizational model also shifts. Centralized BI teams struggle to keep pace with dynamic systems. Ownership needs to move closer to the data. Models inspired by domain-oriented data ownership models become more effective because they distribute responsibility across teams.
BI does not disappear. It shifts from controlling access to guiding standards. That transition introduces friction. Systems built over the years do not adapt overnight. Routing logic, pipeline dependencies, and query assumptions remain embedded in code and infrastructure. Untangling them takes time.
What This Means for CTOs
The shift toward agent-driven analytics is already visible in operations. Three indicators reveal when the semantic layer becomes a bottleneck.
- A large portion of engineering time goes into maintaining definitions that barely get used
- Agent-driven workflows frequently require data outside the modeled layer
- Warehouse spending supports pipelines built for narrow, single-purpose queries
If you are seeing two out of three, you are already at the inflection point.
You do not need to replace everything right away. Existing semantic layers still serve stable dashboards well. The change lies in where new systems grow.
Treat the semantic layer as a legacy asset. Maintain it where it works. Avoid extending it into areas where it creates friction. Route new workloads through architectures designed for dynamic query generation, an approach we at Wisdom AI follow in practice.
That approach reduces risk while enabling a gradual transition.
The Assumptions Have Changed
The semantic layer solved a real problem. It brought consistency to analytics when questions moved at a human pace, and systems could afford to decide meaning in advance.
That environment no longer defines modern data systems.
Agent-driven analytics makes inquiry continuous, often crossing boundaries the model never anticipated. Under that pressure, systems built on predefined semantics begin to show their limits.
The detour was necessary. It gave us a decade of reliable analytics. Now the constraints have changed, and the systems that adapt will shape what comes next.






{kind=link}