
Retail allocation is often opaque. Planners input a purchase order and then wait for the results, which can be challenging to interpret. Some stores receive partial shipments, while others are left out entirely. Overrides become routine, leading to accumulated delays in fulfillment. These delays push the product past its intended floorset or selling window, resulting in late receipts, missed seasonal launches, or stranded inventory.
As inventory ages, it becomes harder to sell at full price, increasing markdown pressure and contributing to excess and obsolete (E&O) stock. Behind the scenes, many allocation engines still depend on slow, heuristic-based logic and batch processing. This article introduces a deterministic, coverage-first allocator designed for real-world fulfillment systems.
It is fast, transparent, auditable, adaptive, and removes the need for guesswork. Instead of relying on sampling and randomness, it provides clear, rules-based outcomes. The engine is flexible enough to support different PO types, store groups, and fallback scenarios through configuration, not engineering changes. Each allocation run takes less than 30 seconds per line, even when the number of stores exceeds the available units.
The engine promotes operational control, fair distribution, and technical rigor. For practitioners involved in building or modernizing retail platforms, it offers a model that eliminates long-tail store exclusions, maintains pack integrity, and allows for real-time observability.
Key Takeaways
- Retail allocation often suffers from opacity and inefficiencies, leading to delays and excess inventory.
- The deterministic, coverage-first allocator provides fast, auditable, rules-based outcomes for allocation processes.
- This system ensures fair distribution by using a coverage-first strategy, guaranteeing that each eligible store receives inventory before any store gets a second unit.
- Pack integrity is maintained throughout the allocation process, ensuring consistent assortments and reducing returns or complaints.
- Full auditability allows planners and engineers to trace decisions, enhancing trust and operational control in retail allocation.
Table of Contents
Traditional Engines Fall Short
In most legacy systems, allocation logic is baked into overnight batch jobs. These pipelines often require external solvers or proprietary rules, producing allocations that take 9 to 12 minutes per PO line. They may also require manual allocation or planner intervention when logic breaks down. When POs span hundreds of lines, processing becomes a multi-hour task. Planners and engineers must wait until the next morning to assess results, fix errors, and re-run adjustments. Backlogs become routine. Override spreadsheets grow.
The process also lacks visibility. When a store gets dropped or a pack is split, there is often no clear explanation. Allocation logic hides behind tuning knobs, legacy code, or third-party decision trees. Planners lose trust. Engineers lose control.
A Deterministic Engine That Guarantees Results
The new system replaces black-box allocation with a deterministic engine that runs in near real-time. It processes each PO line in less than 30 seconds using a rules-based algorithm that calculates exact, whole-unit allocations. There are no external solvers or opaque rules. All decisions follow a transparent, rules-first model with strict fallback and retry gates.
The allocator handles simulation and production runs with the same logic path. It consumes events via streaming or API and returns consistent results every time. This provides engineers with complete control over allocation behavior and outcomes, eliminating delays and surprises.
Coverage-First Logic for Tight-Unit POs
When the number of units is fewer than the number of stores, many engines resort to random sampling. The result is long-term allocation bias. Some stores receive inventory frequently. Others get skipped repeatedly. This leads to planner frustration and inconsistent customer experiences.
The deterministic allocator applies a coverage-first strategy. If 100 units are available for 150 stores, the system ensures that each of the 100 unique stores receives one unit. No store receives a second unit until every other eligible store has received one. This ensures breadth before concentration.
Allocation Logic Snapshot:
- Fractional Split: Demand-weighted ratios are calculated for all eligible stores.
- Coverage Pass: Rounding is applied, and units are allocated to maximize unique store coverage.
- Remainder Distribution: Remaining units are assigned using a rotation-aware mechanism seeded by PO ID and timestamp. Tie-breaks default to ascending alphanumeric store ID unless a custom override is configured.
Example: Consider a PO with 48 units and 64 eligible stores. The engine will assign one unit to each of 48 unique stores in a single pass. The 16 unallocated stores will be prioritized in subsequent allocations to avoid persistent exclusion. No store receives more than one unit until every other store has received one.
For planners who want more control, the engine supports:
- Breadth vs. focus coefficients to tune distribution balance
- Target store counts for specific PO lines
- Store clusters for regional targeting or segmentation
When remainders are rarely left after the initial distribution, the engine uses a need-weighted, rotation-aware strategy. It rotates remainder allocation across stores in a fair, non-repeating pattern, reducing store starvation over time.

Pack Integrity Without Exceptions
Splitting prepacks, case packs, or bundled units can introduce chaos into the fulfillment process. Downstream systems expect consistency. When allocation breaks pack structure, stores may receive incomplete assortments or mismatched quantities. This triggers returns, complaints, and manual intervention.
The allocator preserves pack-size integrity by design. It maintains eaches, prepacks, and case packs as atomic units throughout every stage of the allocation process. It validates integrality after rounding, after applying size curves, and after distributing the remainders.
If integrality checks fail, the engine retries allocation with adaptive thresholds. If all retries fail, it executes a controlled fallback:
- Versioned
- Logged with input parameters and retry history
- Visible through observability dashboards
This ensures pack handling remains stable without relying on planner overrides or post-processing scripts.
Size Curves Applied at the Right Stage
The dynamic size curves model demand variation by store, region, or season. But applying them too early can distort coverage. If a curve heavily favors a few stores before rounding, smaller stores may be dropped.
To prevent this, the allocator applies size curves after rounding. This guarantees that the initial coverage goal is met before adjusting quantities based on demand. Once coverage is locked, the engine applies PO-level size curves to refine per-store quantities.
Each size curve:
- Is supplied dynamically per PO
- Is versioned with a run ID
- Can be replayed exactly for audits or simulations
This sequencing maintains fairness while adapting to actual store-level demand signals.
Full Auditability and Control
Allocation decisions affect fulfillment, revenue, and customer experience. Planners, engineers, and compliance teams need to know how and why decisions were made.
Every run of the allocator produces a fully auditable trail, including:
- Run ID and algorithm version
- Size curve and coefficient set IDs
- Retry thresholds and fallback activation status
- Sum-delta and deviation metrics
- Before-and-after comparisons for reallocation
Quality Gate Criteria:
Before triggering fallbacks, the engine enforces configurable allocation thresholds:
- The difference between the planned quantity and allocated quantity must be less than 10 units.
- Retries are limited to a maximum of 3 passes per PO line.
If these thresholds are exceeded, the allocation is routed to manual review. This ensures control handoffs are predictable and observable without risking system-level failures.
If retries are needed, they happen automatically. If fallbacks are triggered, they are recorded with complete visibility into what thresholds were relaxed. Nothing is silent. Every outcome can be explained and traced.
Key SLIs include:
- Runtime per PO line
- Percent of coverage achieved
- Retry rates
- Fallback counts
- Delta between requested and allocated quantities (sum-delta)
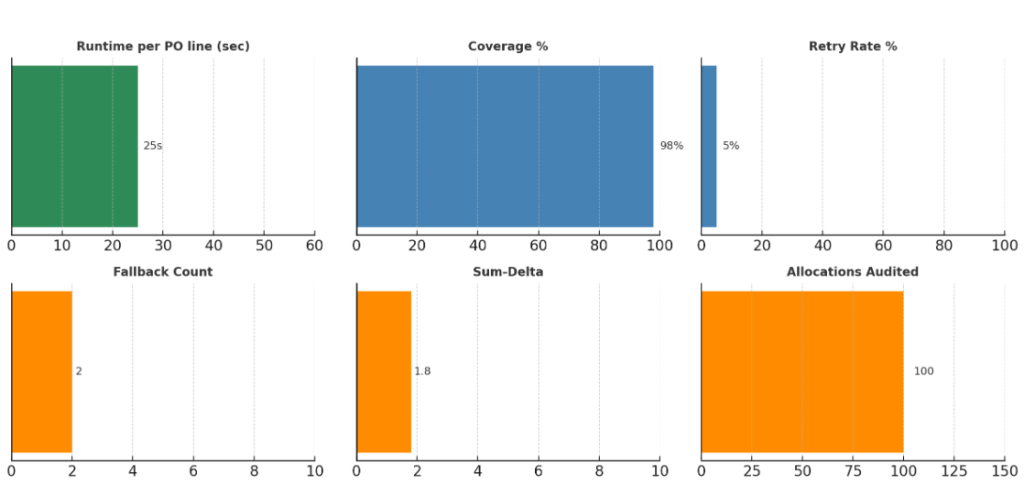
This level of observability supports not only auditing but also continuous improvement. Allocation teams can analyze trends, tune coefficients, and validate updates with confidence.
Reallocation Built In
Inventory changes. PO details shift. Store eligibility updates mid-cycle. Traditional allocation engines treat reallocation as an exception that must be triggered manually.
In this system, reallocation is a first-class capability. When inputs change, the engine automatically re-runs the allocation using the same rules. It produces a diff report between the old and new results, capturing changes in:
- Store-level allocations
- Pack counts
- Coverage percentages
- Allocation fairness and rotation
Engineers and analysts can utilize this tool to simulate “what-if” scenarios or compare outcomes across different seasons, regions, or planning assumptions.
This enables agile planning without the need for hacks, overrides, or workarounds.
Deployment That Doesn’t Disrupt
The allocator runs as a microservice or function that integrates directly with planning systems. It can be triggered via:
- Kafka
- SQS
- Direct REST API calls
It also supports REST-based overrides and simulation modes. This makes it easy to integrate into existing planning workflows without requiring a rebuild.
The system works with:
- Observability stacks and monitoring platforms
- Planning and fulfillment of data pipelines
- Planner-facing tools and dashboards
Rollout can be gradual. Teams can start with specific categories, regions, or PO types. Once validated, the scope can expand. All of this happens without disrupting core planning operations.
Operational Impact
This rules-based coverage-first allocator replaces inconsistent, solver-heavy engines with clear, fast logic. The shift leads to real operational outcomes.
| Metric | Traditional Engines | Deterministic Allocator |
|---|---|---|
| Runtime | 9–12 minutes per line | Under 30 seconds |
| Coverage | Unpredictable | Guaranteed, even with tight units |
| Pack Handling | Often broken | Always preserved |
| Remainder Placement | Random or biased | Fair, rotation-aware |
| Auditability | Minimal or missing | Full, versioned, and replayable |
Planners spend less time debugging outcomes. Fulfillment teams receive consistent shipments. Store experience improves. Analysts gain tools for experimentation and simulation without re-architecting systems.
Conclusion
Store allocation doesn’t need to be slow or random. It doesn’t need to rely on manual overrides, hidden tuning knobs, or post-hoc justifications.
By adopting deterministic logic, enforcing pack-size constraints, correctly sequencing size curves, and logging every retry and fallback, this engine delivers a faster, fairer, and more explainable process.
Each PO line finishes in under 30 seconds. Every eligible store gets a fair chance. Every decision is visible and repeatable.
Coverage-first allocation becomes a capability, not a liability.
References
- Kumar, P. (June 3, 2022). Deterministic Inventory Models. The MBA Institute.https://themba.institute/management-of-machines-and-materials/deterministic-inventory-models/
- Ivanov, D., & Dolgui, A. (2014). Measuring supply chain resilience using a deterministic modeling approach. ResearchGate.https://www.researchgate.net/publication/262191522_Measuring_Supply_Chain_Resilience_Using_a_Deterministic_Modeling_Approach
- Xu, L. (2021). Designing scalable retail fulfillment systems for omnichannel growth (Master’s thesis). MIT Sloan School of Management.https://dspace.mit.edu/bitstream/handle/1721.1/139485/xu-lizaxu-mba-mgt-2021-thesis.pdf?sequence=1&isAllowed=y







{kind=link}